 这是一位 软件工程师 的博客!
这是一位 软件工程师 的博客!
热衷于探索 Linux, AI 和软件开发技术. 😉
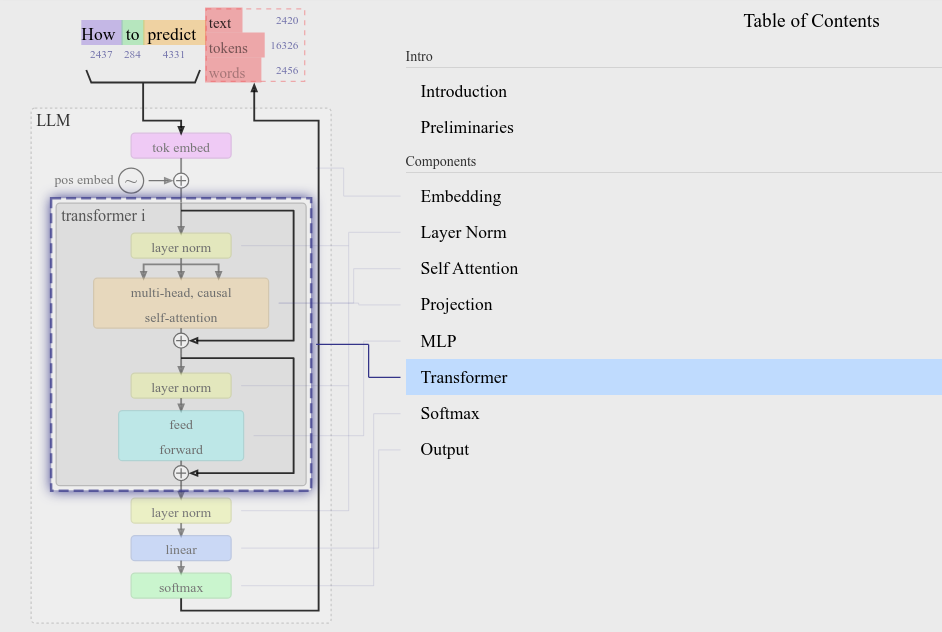
nanoGPT 源码解析:GPT-2 训练、微调及推理
每个看似灵光乍现的比喻,都在Transformer架构的注意力矩阵里早有伏笔 就像骰子在空中旋转时,落点早已被空气动力学方程式锁定 —— DeepSeek 首先回顾一下 OpenAI GPT 系列经典模型: GPT-1 (Radford et al., 2018) 参数规模为 117 M,首次将 Transformer 应用于语言模型,并开创了 NLP 领域无监督 pretrain + 有监督 finetune 的训练范式 GPT-2 (Radford et al., 2019) 最大参数规模为 1.5 B,发现更大规模的模型可以实现 zero-shot,只需 pretrain,不需要 finetune 就能解决下游任务 GPT-3 (Brown et al., 2020) 最大参数规模为 175 B,发现模型具有了 ICL 能力(也就是涌现 emergent),不需要传统的 finetune 步骤,在提示词中提供 few-shot 就能让模型更好地学习下游任务 想要研究 GPT-2 源码,可以参考的实现有 nanoGPT、llm.c、HF Transformers GPT2Model 等。简单起见,我选择 nanoGPT 进行研究,它复现了最小版本的 GPT-2。 Config Config 中存储了 LLM 的一些通用属性,反映了模型的规模和架构特性。 HF Transformers 通过 Configuration 定义模型架构并创建相应的 model。HF Transformers 中不同模型有自己的 Config 类,如 BertConfig, GPT2Config 等,它们具有不同的属性。但它们又都是 PretrainedConfig 的子类,因此也具有一些通用的属性名,如 hidden_size, num_attention_heads, and num_hidden_layers 等。...
Python Modules 机制简述
Module 作为脚本执行 当以 python module.py 运行 module 时,__name__ 会被设置为 __main__,所以在模块尾部添加以下代码可以使该代码仅在 module 作为主文件执行时运行: 1 2 if __name__ == "__main__": pass Module 搜索路径 当导入 spam 这个 module 时,解释器会 先在 sys.builtin_module_names 中搜索,看是不是 built-in modules 如果没有找到,就会在 sys.path 中搜索 spam.py 文件 sys.path 的值从以下位置初始化: 第一个位置:当前脚本所在的目录;若没有指定脚本(REPL),则就是一个代表当前工作目录的空字符串 PYTHONPATH 依赖于安装的默认值(按惯例包含 site-packages 目录) __pycache__ 为了加快 module 的加载速度,Python 将每个 module 的编译版本保存为 __pycache__ 目录下的 module.version.pyc 文件。从 .pyc 文件读取程序的运行速度并不比从 .py 文件读取程序的速度快; .pyc 文件唯一更快的是它们的加载速度。 Packages 注意:所有 packages 都是 modules,但反之不然。换句话说,Package 是一种特殊的 module。特别地,任何包含 __path__ 的 module 被视为一个 pacakge。为便于理解,可以把 module 视为 ....
Step by Step to Build a Blog with PaperMod
Follow Installation doc to install Hugo and PaperMod. Git Submodule Method is recommended, which keeps your repo independent and tidy by seperating your configs and posts from the theme’s source code. Notice: Don’t forget to add a .gitignore file in your repo, like this: 1 2 3 4 /public .DS_Store .hugo_build.lock resources/_gen/ Following are the tutorials of configuring PaperMod. You can reproduce the features by simply copy the corresponding code snippets or just clone my github page repo and replace my posts with yours....
Linux 内核添加自定义系统调用
网上的教程 1 大多使用老版本内核,许多内容已经不再适用了。本文依托于我的项目 mycall 进行讲解,旨在把自己踩过的坑全部记录下来,具体实现请参考源码。实验在 Ubuntu 20.04 amd64 虚拟机(内核版本 5.15.0-105-generic)中进行。 本文将先后介绍给内核添加自定义系统调用的两种方式: 通过内核模块将系统调用插入正在运行的内核中。 将系统调用添加到内核源码中,再重新编译安装内核。 通过内核模块添加系统调用 这个方法最简单但是坑也最多,因为内核开发组显然不希望我们通过内核模块修改/覆盖系统调用 2,并且做了诸多限制,为此我们只能用一些 trick。 定义系统调用 从 Linux 4.17 开始,x86 下系统调用服务例程只接收 struct pt_regs * 一个参数 3。因此系统调用的定义为如下形式: 1 2 3 4 asmlinkage long sys_mycall(struct pt_regs *regs) { ... } 根据 Linux x86 calling convention,Linux 系统调用通过寄存器传递参数:rax 存储系统调用号,rdi 存储第一个参数, etc. pt_regs 就是一个包含了寄存器值的结构体 4,需要从中读取参数。 获取系统调用表地址 要插入系统调用,首先需要能够找到系统调用表的地址 sys_call_table。可惜 2.6 版本以后内核就不再 export sys_call_table 了 5,只能寻求其他办法: 从 System.map 读取 编译内核时生成的内核符号表中包含系统调用表的地址,可以通过以下命令获取: 1 cat /boot/System.map-$(uname -r) | grep sys_call_table 但是若内核开启了 KASLR (Kernel Address Space Layout Randomization),实际地址会和 System....
Hadoop/HDFS 虚拟机集群部署及 MapReduce 实验
大数据软件生态分为三方面: 数据存储:Hadoop HDFS, HBase, KUDU, 阿里云 OSS, AWS S3 数据计算:Hadoop MapReduce, Hive, Spark, Flink 数据传输:Kafka, Pulsar, Flume, Sqoop Hadoop 是一个大数据整体解决方案,包括三大组件:分布式数据存储 HDFS,分布式数据计算 MapReduce 和分布式资源调度 YARN。本科的时候就做过 Hadoop 实验,几年之后对 Hadoop 是啥都几乎没概念了,刚好又需要做个实验,就记录一下实验过程,从简单的 URLs 统计看 Hadoop 和 HDFS 的基本功能。 本实验在虚拟机 VirtualBox 中完成,系统镜像为 Ubuntu。 虚拟机集群部署 准备虚拟机 首先准备三台虚拟机,主机名和配置如下。 节点 CPU Mem ubuntu-server-0 1 4GB ubuntu-server-1 1 2GB ubuntu-server-2 1 2GB 在 Vbox 中将虚拟机网络都配制成桥接模式,以便相互之间可以连通。 设置虚拟机固定 IP,免得重启后发生变动。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 # 1....
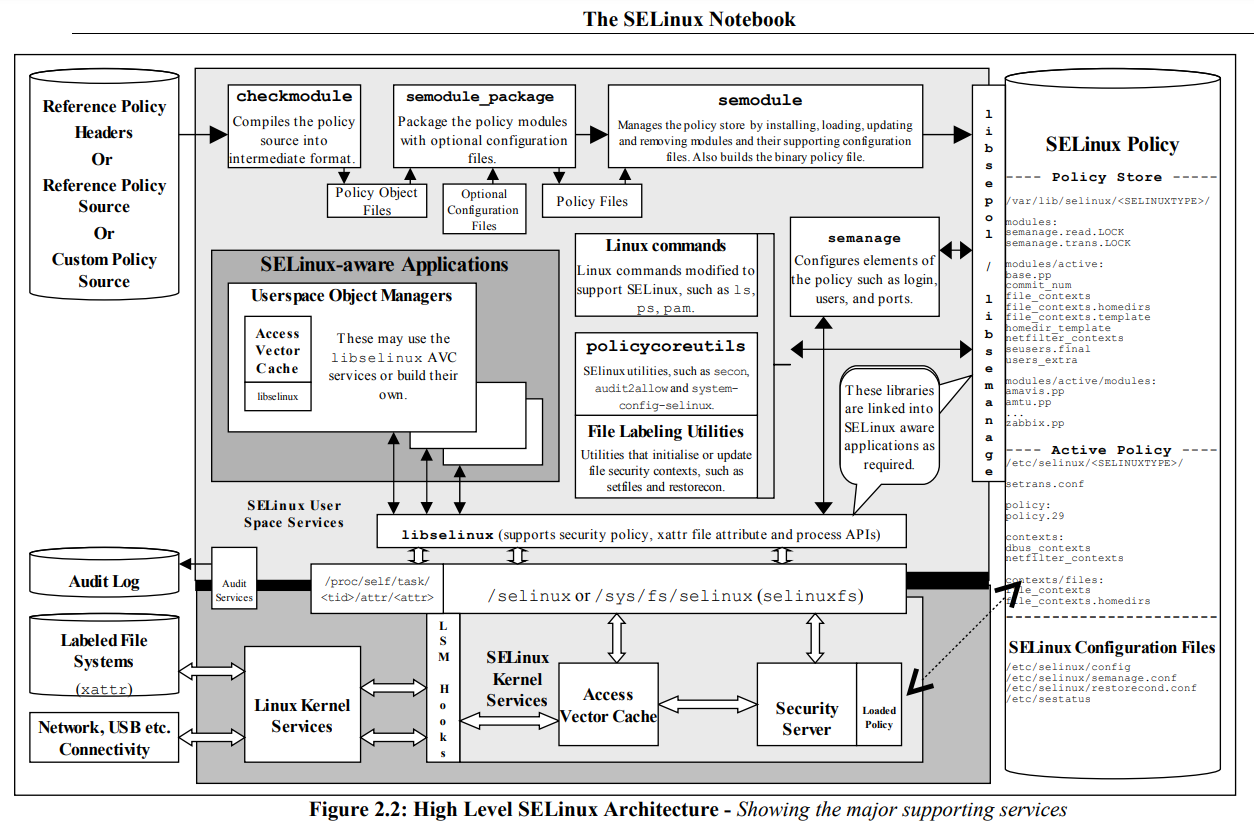
浅尝 SELinux
用 Fedora 的时候,发现系统默认启用了 SELinux,还动不动弹警告窗口,于是稍微研究了一下。 我们平常经常接触的存取控制机制叫做自主式存取控制 (DAC, Discretionary Access Control),如 user/group/other 对文件的 rwx 权限就是 DAC。SELinux 是一种强制式存取控制 (MAC, Mandatory Access Control) 的实现(没错,SELinux 只是最常见的一种 MAC,其实还有 TOMOYO、AppArmor 等等),能够提供更细粒度的权限控制,如某个类型的进程被允许读某个类型的文件。 SELinux 的实现依赖 LSM (Linux Security Modules)。LSM 在很多 Linux 内核服务(如程序执行、文件操作、socket操作、IPC操作、内存段、信号量、sysctl、syslog、audit)中插入了 hook,第三方的存取控制机制如 SELinux、AppArmor、SMACK、TOMOYO 就是利用这些 hook 实现的。 在 SELinux 下,每个进程和资源都被赋予了 SELinux context (i.e. SELinux label),利用这些 context 可以编写一系列 rules 来定义进程和进程之间、进程和资源之间允许哪些交互(白名单方式,除非你在 rule 中显式地允许了,否则 SELinux 默认不允许任何交互,这就是为什么叫做强制式),这些 rules 组合在一起就是 SELinux policy。需要注意的是,DAC 和 MAC 是合作而不是互斥关系,要在通过 DAC 的检查后才能检查 SELinux policy 的 rules ,也就是说如果你的访问连 DAC 都过不去那就不用劳烦 SELinux 了。...
什么样的代码缩进与对齐风格最合适?
区别 Indentation 和 Alignment Indentation 缩进有逻辑上的层级嵌套关系;而 Alignment 对齐逻辑上属于同一层级,存在只是出于美观需要。在如下代码中用 >>>> 代表 Indentation,.... 代表 Alignment。 1 2 3 4 5 6 int main() { >>>>int a = 1 + >>>>........2 + 3; >>>>return 0; } Tab 和 Space 都可用于 Indentation 和 Alignment,根据用法分为多种不同的方案。 Indentation, Alignment 方案 各种语言有自己的推荐的代码风格。 Indentation/size Alignment/size Example Tab/8 Tab/8 Linux C coding style Tab/8 Space/4 OpenBSD C style Space/4 Space/4 PEP8 - Style Guide for Python Code Tab Tab/Space Effective Go 注意上表中的 size 长度都是单位长度,实践中可以根据缩进层级或对齐美观需要使用多个单位。...

虚拟地址空间:局部空间与全局空间 | 用户态与内核态
局部空间与全局空间 32 位机的虚拟地址位数为 32 位,每个任务都有自己独立的 4GB 虚拟地址空间。所谓独立,指的是不同任务相同的虚拟地址映射到不同的物理地址,本质上是依赖每个任务有自己的 PDT/PT。 这 4GB 虚拟地址空间又分为两部分:低端虚拟地址位于局部空间/用户空间、高端虚拟地址位于全局空间/内核空间。虚拟地址的高低端分界线依赖于操作系统的实现,如 Linux 的分界线位于 3GB 处,0 - 3GB 为低端虚拟地址,3GB - 4GB 为高端虚拟地址。 所有任务共享全局空间(所有任务的高端虚拟地址指向相同的内核页表),有各自的局部空间(LDTR 指向当前任务的 LDT,低端线性地址指向各自的页表)。 下图参考《x86 汇编语言 从实模式到保护模式》绘制,虚拟空间中 0 - 2GB 为局部空间,2 - 4GB 为全局空间,所有段均处于平坦模式。 用户态与内核态 特权级是处理器用来区分不同执行环境的一种机制。例如,在 x86 架构中,有四个特权级(Ring 0 到 Ring 3),其中 Ring 0(最高特权级)是内核态,操作系统内核在这里运行,拥有全部权限;Ring 3(最低特权级)是用户态,普通应用程序运行于此,权限受到限制。由固件负责实施特权级保护。 DPL:在描述符中指定,代表着一个段的特权级。 CPL:在 CS 段选择子中指定,代表着当前执行的代码段的特权级。 RPL:在段选择子中指定,代表请求者的特权级。 IOPL: 在 TSS 的 EFLAGS 中指定,代表着当前任务的输入输出特权级。 在绝大多数时候,请求者都是当前程序自己,因此 CPL = RPL。有时可能用户程序需要传入一个选择子作为参数,让内核例程代为访问,进入内核态后 CPL 变为 0,这时操作系统必须负责把这个选择子的 RPL 设置为用户程序自己的 CPL。 特权级在以下场景中发挥作用: 特权指令使用条件:CPL = 0。 访问数据段条件:CPL 和 RPL $\leq$ 目标 DPL。 访问代码段条件:除从高特权级例程返回外,不允许从高到低转移,因为操作系统不会引用可靠性比自己低的代码。一般来说,控制转移只允许发生在两个特权级相同的代码段之间(CPL 和 RPL = 目标 DPL);若目标代码段是依从的,可以从低到高,但转移后不允许改变 CPL(CPL 和 RPL $\geq$ 目标 DPL);还可以通过调用门从低到高(用 jmp far 不改变 CPL,用 call far 会把 CPL 提升到目标 DPL)。 访问调用门条件:目标 DPL $\leq$ CPL 和 RPL $\leq$ 调用门描述符 DPL。 态 !...