每个看似灵光乍现的比喻,都在Transformer架构的注意力矩阵里早有伏笔
就像骰子在空中旋转时,落点早已被空气动力学方程式锁定
—— DeepSeek
首先回顾一下 OpenAI GPT 系列经典模型:
- GPT-1 (Radford et al., 2018) 参数规模为 117 M,首次将 Transformer 应用于语言模型,并开创了 NLP 领域无监督 pretrain + 有监督 finetune 的训练范式
- GPT-2 (Radford et al., 2019) 最大参数规模为 1.5 B,发现更大规模的模型可以实现 zero-shot,只需 pretrain,不需要 finetune 就能解决下游任务
- GPT-3 (Brown et al., 2020) 最大参数规模为 175 B,发现模型具有了 ICL 能力(也就是涌现 emergent),不需要传统的 finetune 步骤,在提示词中提供 few-shot 就能让模型更好地学习下游任务
想要研究 GPT-2 源码,可以参考的实现有 nanoGPT、llm.c、HF Transformers GPT2Model 等。简单起见,我选择 nanoGPT 进行研究,它复现了最小版本的 GPT-2。
Config
Config 中存储了 LLM 的一些通用属性,反映了模型的规模和架构特性。
HF Transformers 通过 Configuration 定义模型架构并创建相应的 model。HF Transformers 中不同模型有自己的 Config 类,如 BertConfig, GPT2Config 等,它们具有不同的属性。但它们又都是 PretrainedConfig 的子类,因此也具有一些通用的属性名,如 hidden_size, num_attention_heads, and num_hidden_layers 等。
| |
类似的,nanoGPT 通过 GPTConfig 类定义模型的属性及其默认值。大模型相关 paper 又有自己惯用的一套表示符号,为方便联系起来理解,对比如下:
| BERT | GPT-2 | GPT-3 | nanoGPT | GPT-2 117M | ||
|---|---|---|---|---|---|---|
| 上下文长度 | - | - | $n_{ctx}$ | GPTConfig.block_size | 1024 | |
| 隐藏层数量 | $L$ | - | $n_{layers}$ | GPTConfig.n_layer | 12 | |
| 注意力头数量 | $A$ | - | $n_{heads}$ | GPTConfig.n_head | 12 | |
| 词嵌入向量维度 | $H$ | $d_{model}$ | $d_{model}$ | GPTConfig.n_embd | 768 | |
| 词表大小 | - | - | - | GPTConfig.vocab_size | 50257 |
- 上下文长度:指的是模型可接受输入的 token seq 长度,这是固定的,若更短则应填充,若更长则应截断
- 隐藏层数量:指的是 Transformer 块堆叠的数量
- 注意力头数量:指的是每个 token 对应的注意力头的数量
- 词嵌入向量维度:指的是 token id 对应的嵌入向量的维度
- 词表大小:指的是 Tokenizer 中所有 token 的集合大小
nanoGPT 代码中,还有一些变量用于表示张量的维度,习惯后对于阅读代码有帮助:
B: batch sizeT: sequence length,等同于block_sizeC: embedding size,等同于n_embdnh: number of heads,等同于n_headhs: head size,等同于n_embd/n_head
Tokenizer
nanoGPT 使用 tiktoken 加载 GPT-2 的 BPE 分词器,将连续文本分割成 token,再输出这些 token 在 vocab 中的索引,即 token ids 序列。可以在 OpenAI Tokenizer 体验 BPE 分词器的效果。
nanoGPT 中还实现了一个简易的字符级分词器,对一段较短的 shakespeare 文本进行分词,我们可以通过它一窥 tokenizer 的原理。
- 读取一段连续的 shakespeare 剧本,如下:
| |
- 按字符进行分割,得到无重复的字符集合作为 vocab:
| |
- 实现
encode/decode函数。encode将字符串映射为 token id 序列,decode反之。
Tokenize 过程的代码如下:
| |
上面代码中,值得注意的还有划分训练集和测试集的方式,就是简单地把连续文本划分为两部分,训练集 90%,测试集 10%。
DataLoader
HF Transformers 中通过 DataLoader 从数据集中采样出一个 batch 的数据,nanoGPT 通过 get_batch 函数实现了类似的功能。
- 在数据集中随机选出
batch_size个起点,每个起点后连续采样block_size个 token id 得到(batch_size, block_size)的 token id seq,作为一个 batch 的输入数据 x - 输入数据 x 每行向后偏移一个 token,仍为
(batch_size, block_size),作为一个 batch 的标签数据 y
输入数据 x 中每个 token id 经过模型 forward 后会输出一串长度为 vocab_size 的预测分数 logits(见 Model 章节),而标签正是输入数据 x 向后偏移一个位置的 token id。
| |
Model
GPT-2 的模型架构还是比较简单清晰的。Figure 1 截图自 LLM Visualization,这是一个非常好的 GPT 模型架构交互式可视化网站。该图所示和代码实现完全一致,可以比对着看。
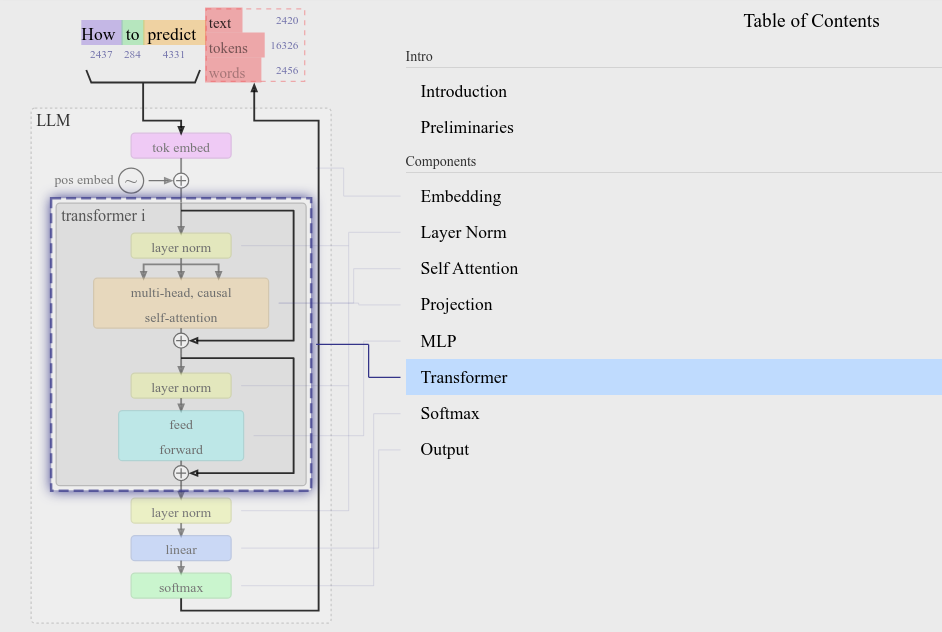
Figure 1. GPT-2 architecture.
(Image source: LLM Visualization)
模型各组件的定义(__init__)以及组装起来的前向传播过程(forward)代码如下:
| |
模型结构中值得注意的有以下几处:
- Token embedding 和 position embedding 都是根据正态分布随机初始化的,负责将 token id 映射为
n_embd维度的嵌入向量。 lm_head是一个模型头,对应于 HF Transformers 的 Model heads。对于语言模型,生成文本任务需要的是分类头,因此lm_head是一个线性层,负责将 transformer 块输出的n_embd维度向量映射到vocab_size维度的 logits。训练时这个 logits 可以直接用于计算误差,但推理时还需要经过 Softmax 转换为采样概率。- Token embedding 和
lm_head共享权重(Weight Tying)
模型的训练和推理都是通过 forward 函数在模型中进行前向传播。可以印证的是,Transformer 是一种 Seq2Seq 模型,每次 forward 同时处理序列中所有 token,同时预测每个 token 的 logits 分数,这个 logits 对应的是下一个 token 的概率。因此输入一段序列,可以同时预测序列中每个 token 的下一个 token,计算所有交叉熵误差的平均,这就解释了为什么训练时标签数据 y 要传入一串连续的 token id 而不是一个。
Transformer
对模型整体有了概念,接下来研究核心模块——Transformer 块。GPT-2 的 transformer 块和 GPT-1 有所不同。对比 Figure 1 和 Figure 2 发现,GPT-1 的 transformer 块遵循 Self-attention 原论文 (Vaswani et al., 2017) 中的 decoder-only transformer 架构,采用后置层正则化(Post-LN),而 GPT-2 采用的是前置层正则化(Pre-LN)。大多数模型都采用前置来增强训练稳定性,尽管这会影响模型性能 (Zhao et al., 2023) 。 1
Figure 2. GPT-1 transformer architecture.
(Image source: Radford et al., 2018)
nanoGPT 的 transformer 块由 Block 类定义:
| |
MHA (Multi-Head Attention)
Transformer 块中最重要的是 CausalSelfAttention 层,实现了 MHA。李宏毅的 ML 课程是一个比较好的入门课程,尤其是对自注意力机制的教学非常通俗易懂,令我印象深刻。
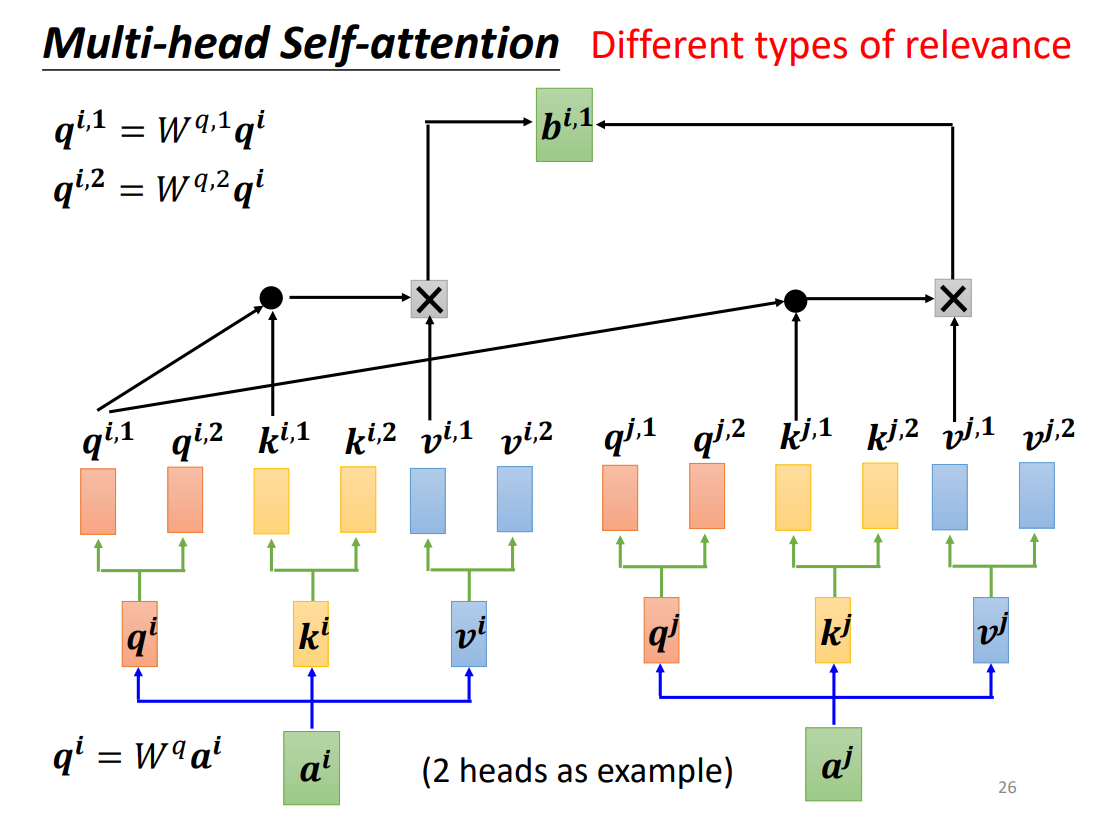
Figure 3. Multi-head Self-attention.
(Image source: 李宏毅 ML 课程 PPT)
但是上图并没有详细描述计算过程,因此我根据 nanoGPT 源码绘制了 Figure 4。

Figure 4. Multi-head Self-attention. (2 heads)
- 每个 token 的嵌入线性映射到
n_embd大小的 Q, K, V 向量。 - 每个 token 的 Q, K, V 向量分别等分为
n_head份,按1 ~ n_head编号,每份n_embd/n_head大小。 - 对于 1 号注意力头,用每个 token 的 1 号 Q 和所有 token 的 1 号 K 相乘,得到 1 号注意力分数矩阵
(T, T)。其他注意力头计算同理,也就是得到n_head个注意力分数矩阵(T, T)。 - 注意力矩阵进行单向掩码和 Softmax,实现单向注意力,变为下三角矩阵。

Figure 5. Causal mask.
- 对于 1 号注意力头,用 1 号注意力分数矩阵和所有 token 的 1 号 V 相乘,得到每个 token 的 1 号输出向量,形状为
(T, n_embd/n_head)。其他注意力头计算同理,也就是得到n_head个输出向量(T, n_embd/n_head)。 - 每个 token 不同注意力头的输出向量合并,得到最终的输出向量
(T, n_embd)。
MHA 的实现代码如下:
| |
PyTorch 的 torch.nn.functional.scaled_dot_product_attention (Scaled Dot Product Attention, SDPA) 提供多种实现(FlashAttention-2, Memory-Efficient Attention, PyTorch implementation),默认情况下会根据输入自动选择最佳实现 2。不过 SDPA 了解一下就可以了,在使用 Transformers/PyTorch 时偶尔会见到,为了理解注意力分数的计算过程我们还是重点关注手动实现版本。
想要明白代码中 Q, K, V 之间的矩阵乘法,先要搞清楚高维张量乘法的计算。@ 操作符其实就是 torch.matmul3,它会将最后两维视为矩阵,多余的维度视为批处理维度,若两个高维张量的批处理维度不一致,可以进行广播 4。批处理维度按照逐元素乘积,矩阵进行矩阵乘法,见下面这个 gist 示例。
因此计算 Q @ K (B, nh, T, hs) x (B, nh, hs, T) 时,注意力头之间是相互独立的,即序列中不同位置 token 的 1 号 Q 只会和 1 号 K 相乘。
Training & Inference & Finetuning
训练和推理区别不大。从 Model 章节中的 GPT.forward 函数可以看出,训练和推理在模型中前向传播的逻辑一致,区别就在于:
- 输入一整个 token seq 还是只需输入最后一个 token
- 是否需要标签 y 计算 loss
但是模型前向传播输出的只是 logits,要得到推理的 token,还要让 logits 通过 Softmax (with temperature) 和 Decoding Strategy 得到预测的 token id,最后将 token id decode 为 token(见 Tokenizer 章节)。这个过程大有文章,不仅直接决定了模型的输出,还能通过调整 logits 的分布给生成文本打水印 5。
在推理环节中,温度和 Decoding Strategy 是非常影响模型输出质量的两个因素。
Decoding Strategy 有很多 6,常见的几种如:
- Greedy Search:这是最简单的策略,直接取概率最大的 token。
- 缺点:生成较长的输出时,可能会产生高度重复的结果。
- Beam Search:每一次迭代保留 num_beams 个概率最大的 token,最终选择联合概率最大的一个序列。
- 优点:可以保留初始 token 概率较低的高概率序列。
- 缺点:Beam Search 是最拖慢推理速度的组件 (Wang et al. 2024)。
- Top-k Sampling:按概率排序 vocab,保留概率最大的 k 个 token,归一化后就在这 k 个 token 中采样。
- Top-p Sampling:按概率排序 vocab,保留从前往后累积概率超过阈值 p 的 token,归一化后进行采样,这样可以根据分布动态调整候选 token 的数量。
温度是用来缩放 logits 的一个超参数,当使用基于概率采样的 Decoding Strategy 时,温度越小,输出多样性越低,反之温度越大,输出多样性越高。因为小于 1 的温度会拉大候选 token 之间的概率差距,使模型更倾向于采样概率较大的 token。极端地说,当最大的采样概率达到 0.999,模型几乎必定采样这个 token,因此对于同样的输入,不管尝试多少次都只会产生一样的回答。若温度较大,各个候选 token 的采样概率分布会变得相对平均,“王侯将相宁有种乎!”,概率相对较小的 token 也不是没有逆袭的机会。
nanoGPT 的推理由 generate 函数实现,Decoding Strategy 选择的是 Top-k Sampling:
| |
你可能注意到上面的 GPT 类还有个 from_pretrained 方法,这是我们想要使用 HF 上预训练模型常用的一个方法。它的原理就是从 HF 下载预训练权重,然后根据 Config 实例化一个模型类,将模型的 state_dict 替换为预训练权重。
微调和预训练没啥区别,只不过微调是加载了预训练模型的参数,并采用更小的学习率开始训练。查看 nanoGPT README#finetuning 会发现,执行训练是通过 python train.py,而执行微调是通过 python train.py config/finetune_shakespeare.py,主要区别就在于微调需要将 init_from 变量从 “scratch” 改为 “gpt2-xl”,从而加载 HF 上预训练模型的参数。
| |
KV Cache
可惜的是 nanoGPT 没有实现 KV Cache,因此本章参考 nanoGPTplus 的实现进行理解。从代码上看,nanoGPTplus 并不是 nanoGPT 的 fork 而是完全重构了,功能更全,但相应的也更加复杂。
推理时,有没有启用 KV Cache 的区别就在于传入模型进行前向传播(隐式执行的 forward 函数)的上下文范围。由于 nanoGPT 没有实现 KV Cache,每次迭代 for _ in range(max_new_tokens) 都需要输入整个序列的 idx(不超过上下文长度限制的情况下),因此每次迭代都需要重新计算完整输入序列的 Q, K, V。而实现了 KV Cache 的 nanoGPTplus,传入模型的上下文范围和所处阶段有关:
- Prefill 阶段:若没有启用 KV Cache,或启用了 KV Cache 但处于第一次迭代且输入序列长度大于 1,应该截取最后 context_size 个 token 作为上下文,生成第一个 token
- Decoding 阶段:若启用了 KV Cache 且不处于第一次迭代,则只取最后一个 token 作为上下文,不断生成下一个 token
| |
在启用 KV Cache 且不处于第一次迭代的情况下,会同时将 KV Cache 和上一次迭代生成的一个 token 输入模型进行前向传播。传播到 CausalSelfAttention 模块时,由于传入的上下文长度为 1,因此实际只计算了这一个 token 的 K, V,和对应 Transformer 层的 KV Cache 合并后就可以得到完整的上下文 K, V,再进行后续的自注意力计算。
| |
但是这个实现还是有点问题,当前这个 token 和之前上下文的 KV Cache 合并后上下文长度变长了,注意力掩码的形状应该与该长度匹配 7。
https://huggingface.co/docs/transformers/main/en/model_doc/gpt2#using-scaled-dot-product-attention-sdpa ↩︎
https://pytorch.org/docs/stable/generated/torch.matmul.html ↩︎
https://huggingface.co/docs/transformers/generation_strategies#watermarking ↩︎
https://huggingface.co/docs/transformers/generation_strategies ↩︎
https://huggingface.co/docs/transformers/kv_cache#under-the-hood-how-cache-object-works-in-attention-mechanism ↩︎