nanoGPT 源码解析:GPT-2 训练、微调及推理
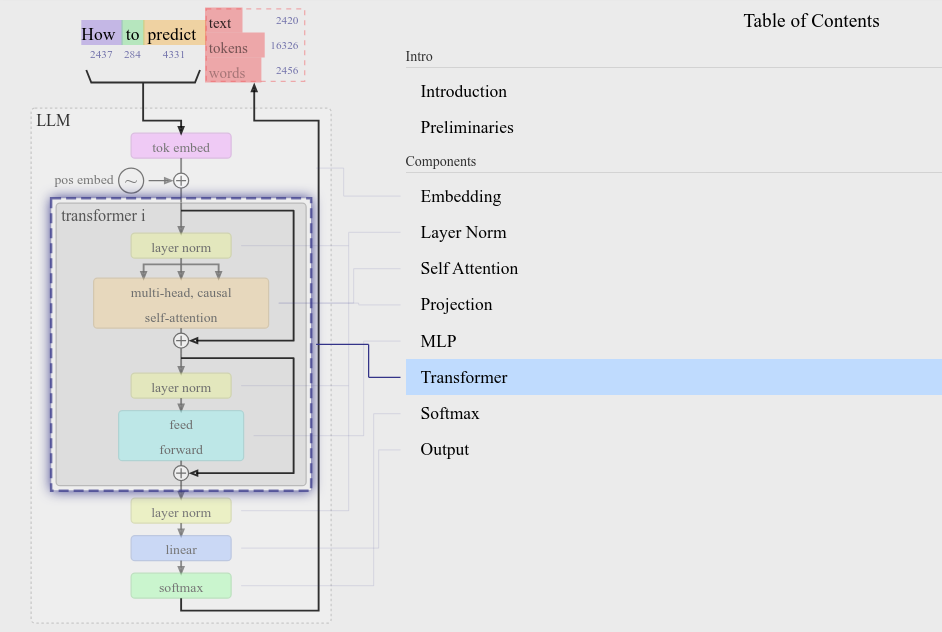
每个看似灵光乍现的比喻,都在Transformer架构的注意力矩阵里早有伏笔 就像骰子在空中旋转时,落点早已被空气动力学方程式锁定 —— DeepSeek 首先回顾一下 OpenAI GPT 系列经典模型: GPT-1 (Radford et al., 2018) 参数规模为 117 M,首次将 Transformer 应用于语言模型,并开创了 NLP 领域无监督 pretrain + 有监督 finetune 的训练范式 GPT-2 (Radford et al., 2019) 最大参数规模为 1.5 B,发现更大规模的模型可以实现 zero-shot,只需 pretrain,不需要 finetune 就能解决下游任务 GPT-3 (Brown et al., 2020) 最大参数规模为 175 B,发现模型具有了 ICL 能力(也就是涌现 emergent),不需要传统的 finetune 步骤,在提示词中提供 few-shot 就能让模型更好地学习下游任务 想要研究 GPT-2 源码,可以参考的实现有 nanoGPT、llm.c、HF Transformers GPT2Model 等。简单起见,我选择 nanoGPT 进行研究,它复现了最小版本的 GPT-2。 Config Config 中存储了 LLM 的一些通用属性,反映了模型的规模和架构特性。 HF Transformers 通过 Configuration 定义模型架构并创建相应的 model。HF Transformers 中不同模型有自己的 Config 类,如 BertConfig, GPT2Config 等,它们具有不同的属性。但它们又都是 PretrainedConfig 的子类,因此也具有一些通用的属性名,如 hidden_size, num_attention_heads, and num_hidden_layers 等。...